AhrefsBot is the crawler operated by Ahrefs. Site owners usually notice it in server logs, CDN analytics, robots.txt reviews, or crawl-budget conversations after SEO-tool traffic becomes visible. Ahrefs keeps its own official bot documentation, so use that page as the source of record rather than copying a user-agent string into a policy and forgetting it.
The useful decision is not "good bot or bad bot." It is two separate decisions. First, does Ahrefs data help the SEO team enough to justify the crawl load? Second, has the traffic been verified well enough for security to treat it as the declared crawler rather than a spoofed one? Mixing those questions is how teams end up with crawler rules no one owns.
What AhrefsBot Is
AhrefsBot is a declared SEO crawler. It gathers web data that supports Ahrefs products, including backlink and content intelligence. Ahrefs also operates AhrefsSiteAudit for site-audit crawling. These crawlers may be useful to SEO teams, but they are not required for Google indexing.
1. The official role
Its role is commercial SEO data collection. A site may want to be represented accurately in Ahrefs because the SEO team uses Ahrefs for backlink checks, competitor research, or technical audits. That benefit is indirect, but for many teams it is still worth allowing on public pages.
2. What it is not
AhrefsBot is not Googlebot. Blocking it should not directly block Google Search indexing, although it can change how the site appears inside Ahrefs products. It is also not automatically hostile. Treat it as an optional crawler: useful in some workflows, unnecessary in others, and worth limiting when load, licensing, or content exposure matters more than SEO-tool visibility.
Should You Allow or Block AhrefsBot?
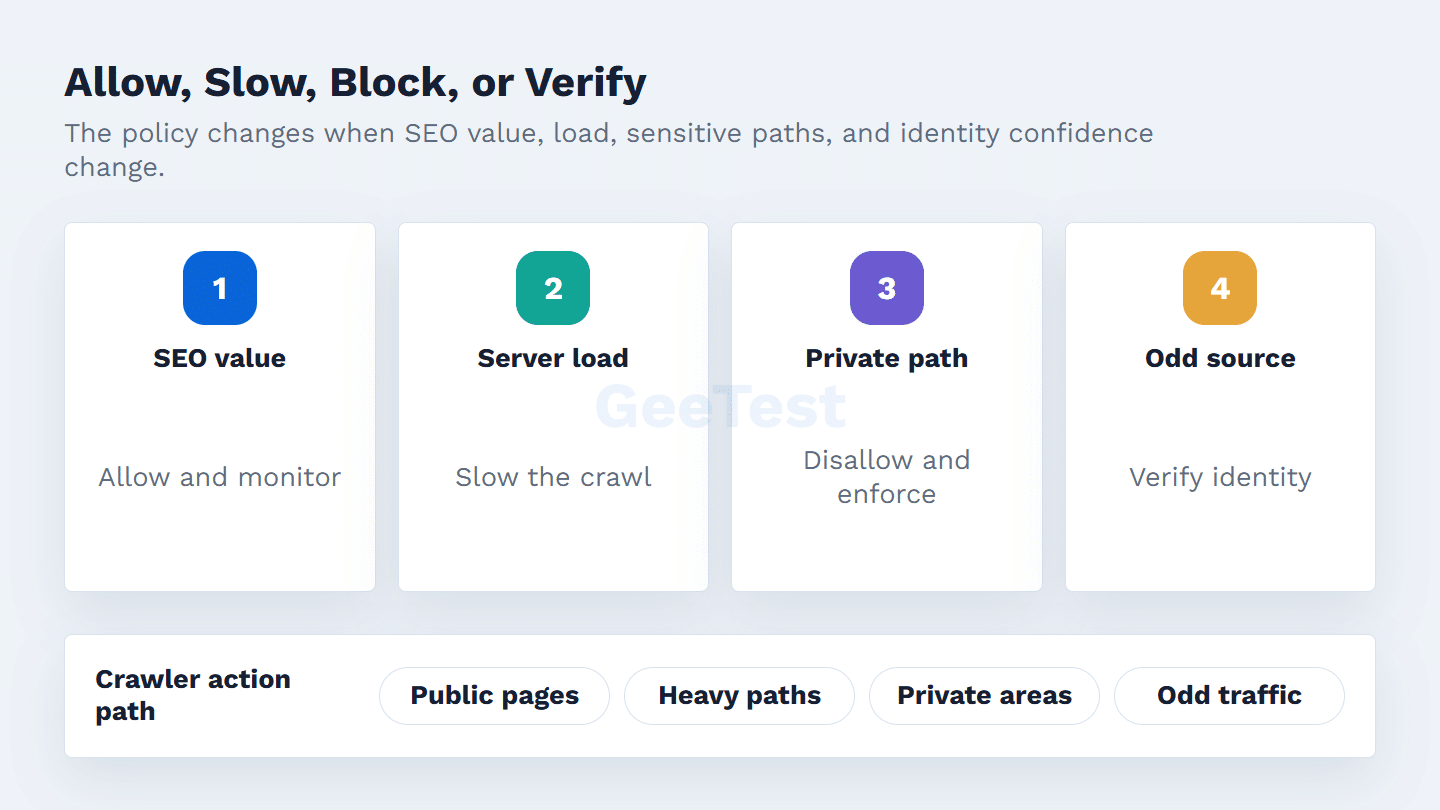
Most sites do not need an extreme rule. Decide by section, document the owner, and revisit the policy when crawl volume or SEO priorities change.
| Situation | Recommended action | Why |
|---|---|---|
| SEO relies on Ahrefs data | Allow and monitor | The crawler supports external SEO intelligence |
| Crawl volume creates load | Add crawl-delay or edge rate controls | This reduces pressure without a full block |
| A section is private, paywalled, or low-value for SEO tools | Disallow in robots.txt and enforce access controls where needed | robots.txt is a request, not a privacy system |
| Logs show an AhrefsBot user-agent from suspicious infrastructure | Verify before trusting | User-agent text can be copied |
| Traffic ignores policy or hits sensitive paths aggressively | Treat it as bad bot traffic | Behavior matters more than the claimed name |
For many teams, the middle ground works: allow public pages that benefit SEO analysis, disallow expensive or irrelevant paths, and monitor the crawl impact. A stricter policy is easier to justify when a site has licensed content, sensitive directories, heavy dynamic pages, or competitive data exposure.
How to Control AhrefsBot
Ahrefs documents its robots.txt token and crawl-delay support on the AhrefsBot page. A basic path-level rule can look like this:
User-agent: AhrefsBot Disallow: /private-or-expensive-path/
To slow the crawler where supported:
User-agent: AhrefsBot Crawl-Delay: 10
This is a request to a cooperative crawler. Google’s robots.txt documentation is a useful boundary reminder: robots.txt communicates crawl preferences, but it is not access control. If content must stay private, use authentication, authorization, server rules, or another enforceable control.
AhrefsBot vs Spoofed Crawlers
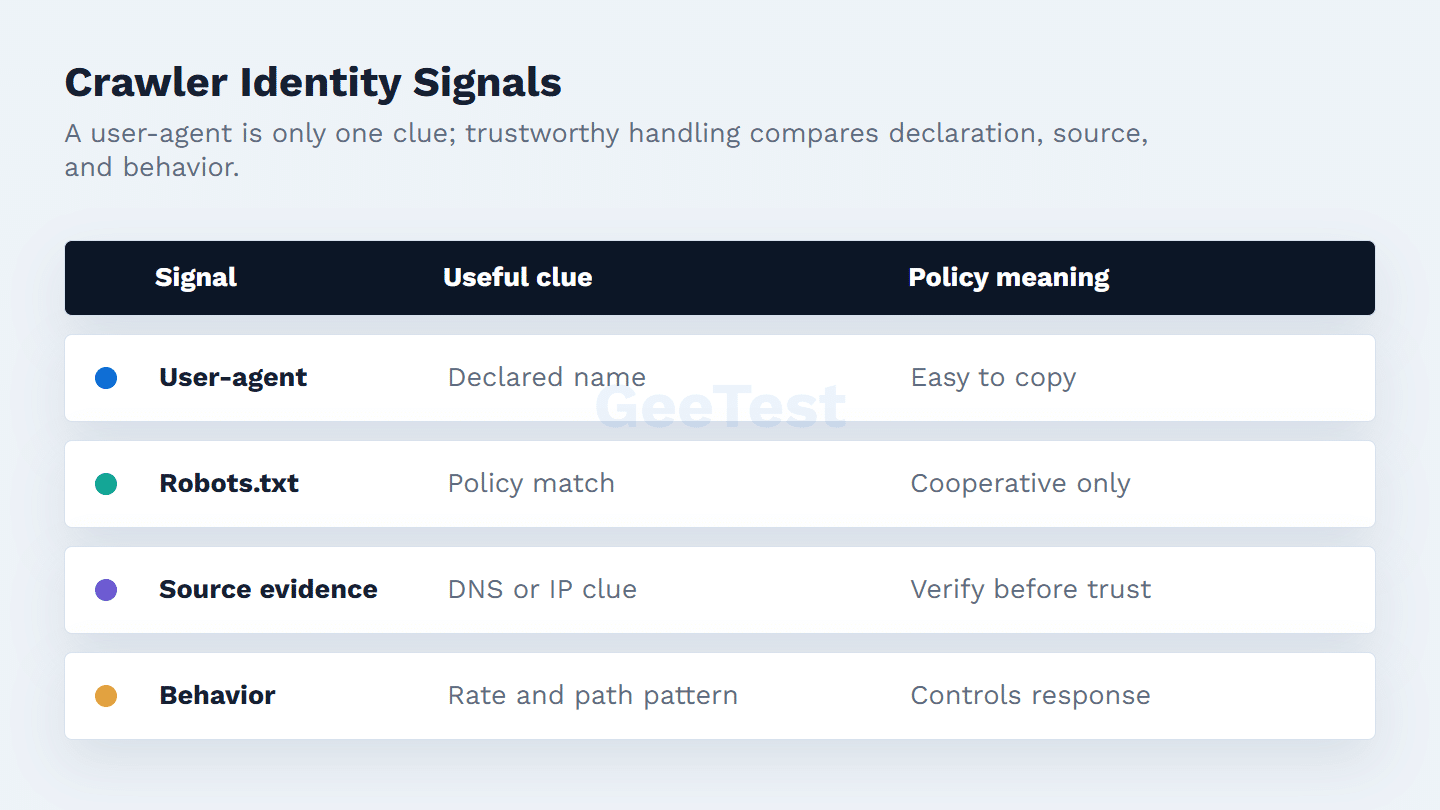
The user-agent is a routing clue, not proof. A low-cost scraper can call itself AhrefsBot and still behave like a scraper. Security teams should compare the declared name with source evidence, request paths, timing, error patterns, and robots.txt behavior.
A legitimate crawler tends to follow a recognizable policy path. A spoofed crawler often shows itself through odd timing, aggressive retries, sensitive-path probing, high error rates, or refusal to respect declared crawl rules. If the site uses bot-management controls, keep crawler rules separate from human-user risk rules. A public article page and a login API should not receive the same response just because the claimed bot name is the same.
What to Monitor in Server Logs
Watch the user-agent, source network, requested paths, status codes, crawl rate, response size, cache hit rate, and whether the crawler respects disallowed areas. Also watch the business side: does the crawl help SEO workflows, or is it mostly cost?
Useful alerts are usually simple. Flag sudden crawl spikes, requests to private-looking paths, repeated 4xx or 5xx responses, ignored robots.txt preferences, and traffic that claims AhrefsBot while behaving unlike a cooperative crawler. If the traffic is high risk, GeeTest bot management concepts can help separate crawler governance from abuse response.
Team Workflow for Crawler Governance
Start with a small crawler register. Record crawler name, user-agent token, source-of-record documentation, business owner, allowed paths, disallowed paths, expected crawl rate, and verification method. Keep AhrefsBot and other SEO crawlers separate from search-engine crawlers, AI crawlers, uptime monitors, and partner integrations.
Then connect the register to enforcement. robots.txt handles cooperative crawlers. CDN or edge rules can manage load. Access control protects private content. Bot-management rules handle spoofing or abusive behavior. Review the register after migrations, infrastructure changes, SEO tooling changes, or unusual log patterns.
The register prevents every incident from becoming a fresh debate. SEO can explain the value. Security can explain the verification standard. Engineering can see the operational rule. Support can answer basic questions if a partner or analyst asks why a crawler was limited.
FAQ
1. Is AhrefsBot good or bad?
It is a declared SEO crawler. It can be useful when your team relies on Ahrefs data, but it is optional. Allow, slow, or block it based on SEO value, server load, content sensitivity, and identity verification.
2. Will blocking AhrefsBot hurt Google rankings?
Blocking AhrefsBot should not directly hurt Google indexing because it is not Googlebot. It may affect how your site appears in Ahrefs products and SEO workflows.
3. How do I stop AhrefsBot from crawling?
Use the AhrefsBot robots.txt token documented by Ahrefs, and add server-side controls for content that truly must not be accessed. robots.txt alone is not a security control.