

Data harvesting is the collection of information from websites, apps, APIs, accounts, forms, public pages, or user interactions so the data can be stored, organized, analyzed, reused, sold, or fed into automated systems. Some of that collection is expected. Product analytics, fraud monitoring, access control, support, and research all depend on governed data movement.
The risk starts when collection becomes excessive, hidden, automated, or detached from the purpose users and site owners understood. For operators in 2026, that makes data harvesting more than a privacy-policy topic. It overlaps with web scraping, crawler abuse, account attacks, fake accounts, credential intelligence, AI training-data extraction, pricing theft, inventory monitoring, and API resource abuse.
What Exactly Is Data Harvesting?
Data harvesting is broader than a single scrape. It includes the collection path, the preparation of the dataset, and the later use of that data. The source might be a public article, a product page, a mobile app endpoint, a profile page, an API response, a transaction flow, or an account area.
Context decides whether the same act feels normal or abusive. A company collecting consent-based analytics for product reliability is different from an automated actor pulling profiles, prices, reviews, or account clues at scale. Public crawl datasets are not automatically malicious either. Common Crawl, for example, describes its work around transparency and public-good access. Enterprise risk appears when extraction ignores policy, targets protected data, overwhelms systems, or reuses content and user signals without an acceptable basis.
Data Harvesting vs Web Scraping, Mining, and Tracking
These terms are related, but they point to different control questions. Web scraping is an extraction method, usually from websites or web apps. Data mining analyzes an existing dataset for patterns. Online tracking follows behavior across sessions, apps, sites, or devices. Data harvesting is the wider collection and preparation activity that can include all of those pieces.
That distinction helps teams choose the right response. Privacy teams focus on notice, consent, minimization, retention, and third-party collection. Fraud and security teams look at bots, crawling, account behavior, device signals, API quotas, and abuse response.
Is Data Harvesting Legal?
Legality depends on the source, jurisdiction, data type, consent, contract terms, purpose, and method. Public availability does not automatically make large-scale extraction safe. Companies should review privacy law, terms of service, intellectual-property boundaries, security duties, and sector-specific rules with legal counsel.
The FTC guidance on website and app data collection is useful because it names everyday collection mechanisms: cookies, pixels, identifiers, app permissions, and tracking technologies. For businesses, those mechanisms need governance. For site operators, hidden or excessive third-party collection can become a trust problem even when the harvesting script was added by a vendor.
How Data Harvesting Works Behind the Scenes
Modern harvesting rarely announces itself as one crawler. A campaign may scrape pages, run browser automation, watch cookies or pixels, call mobile APIs, create accounts, reuse compromised credentials, or normalize content into an AI data pipeline. The technical entry point changes, but the business pattern is the same: a system tries to collect more useful data than the site intended to expose.
APIs deserve special attention because they often return structured records faster than HTML pages. A weak page may leak content slowly; a weak API can expose records cleanly and repeatedly. API owners need authentication, authorization, quotas, response-size limits, anomaly monitoring, and an abuse response path. OWASP API4:2023 Unrestricted Resource Consumption is a helpful reference for volume, cost, and resource-control failures.
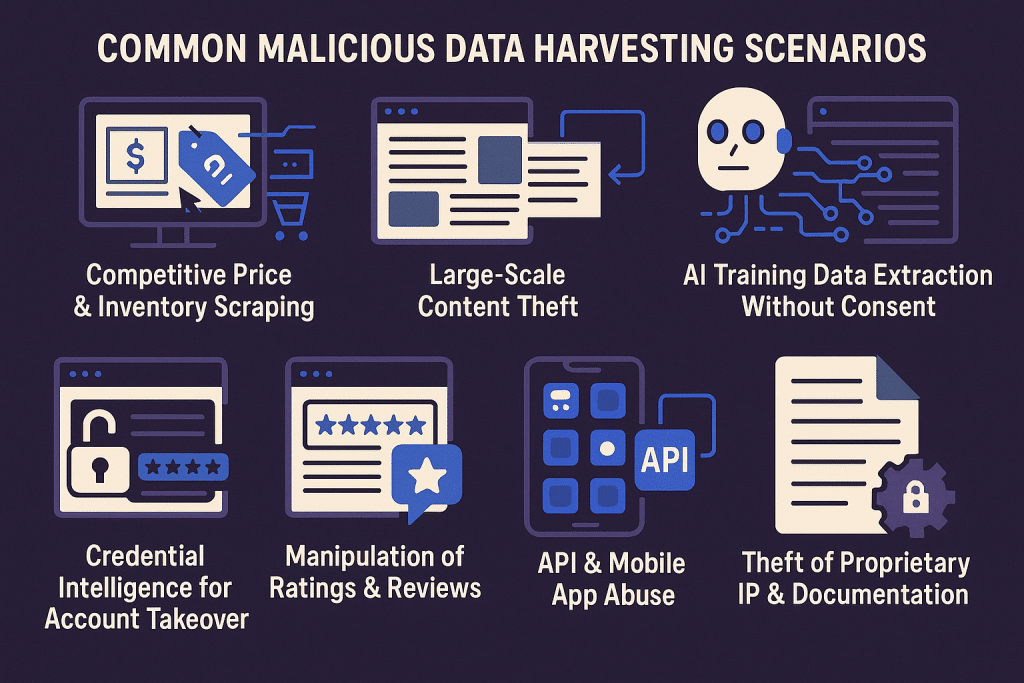
Common Malicious Data Harvesting Scenarios
Some harvesting is about competitive intelligence: prices, stock levels, discount rules, and availability are pulled from e-commerce, travel, and retail platforms. Related GeeTest guidance on e-commerce fraud protection covers adjacent marketplace abuse.
Other campaigns target content, account clues, or user signals. Publishers and SaaS platforms may see original content copied into clone sites or unauthorized datasets. Attackers may gather usernames, profile details, and login-flow metadata for credential stuffing or account takeover. Review, seller, and reputation signals can also be harvested to support fake reviews or marketplace manipulation.
How Data Harvesting Hurts Enterprises
The damage is not limited to copied content. Scraped prices, availability, product attributes, and proprietary assets can weaken market advantages. Bot traffic can distort demand signals, conversion analysis, inventory planning, and campaign performance. Repeated automated requests consume bandwidth, compute, search capacity, API quotas, and engineering time.
There is also a fraud path. Harvested emails, usernames, account metadata, and behavioral clues can support account takeover, spam, fake accounts, coupon abuse, and social engineering. Overly aggressive defenses create another problem: legitimate users, search crawlers, or partners may be blocked if traffic is judged only by IP, user agent, or a static threshold.
The operational cost is often hidden in small tickets. Search gets slower, inventory reports look odd, fraud teams see more account probes, and marketing analytics become less reliable. A single scrape may not look severe, but repeated extraction can change how teams read demand, risk, and conversion data.
For executives, the question is not only "Was data copied?" It is "Which decision now depends on polluted or exposed data?" Pricing, campaign spend, marketplace trust, fraud rules, and customer support can all be affected when harvesting becomes part of the background traffic.
How to Stop Malicious Data Harvesting in 2026
The strongest response is layered. Start by reducing what can be collected: remove unnecessary fields, limit generous pagination, avoid default bulk export paths, and keep private data behind authentication and authorization. Use robots.txt for cooperative crawlers, while remembering that Google’s robots.txt documentation treats it as a crawl instruction, not an access-control system.
High-value flows need more than perimeter filtering. Search, listing, login, checkout, coupon, review, account recovery, and export pages should use scoped access, per-account quotas, response-size limits, device and session history, and alerts for unusual enumeration or export behavior. When a request moves from browsing to unlocking value, the response can become stricter.

Device Fingerprinting can support device-level risk analysis, especially when IP rotation hides repeated automation. It should remain one signal in a broader policy that also considers behavior, account history, flow sensitivity, and false-positive risk.
At sensitive moments, risk-based verification can make extraction harder without treating every visitor as hostile. GeeTest can be positioned as a behavior-driven verification and risk-control option for signup, login, checkout, review submission, coupon use, bulk search, account recovery, and data export. The limits of traditional CAPTCHAs matter here because static challenges can add friction without stopping advanced harvesting pipelines.
Prioritize controls by surface value. Public educational pages may need crawler policy and monitoring. Product, pricing, inventory, review, and profile pages may need pagination limits, cache design, and anomaly alerts. Logged-in flows need authorization, session integrity, device history, and step-up checks. API and export endpoints need scoped tokens, quota, response-size limits, and clear audit trails.
Avoid treating every crawler as the same risk. Verified search crawlers, SEO tools, partner integrations, AI crawlers, uptime monitors, and unknown automation each need a source of record, allowed paths, expected volume, and escalation owner. A crawler register prevents the team from swinging between two bad defaults: allow everything that names a known bot, or block everything that looks automated.
Build an Operating Review Loop
Data harvesting risk changes when a site launches new APIs, exposes new account features, adds third-party tags, changes search pages, expands to a new market, or becomes more visible to scrapers. Review controls after product releases, traffic spikes, privacy-policy updates, search-indexing issues, and support complaints.
The review should include privacy, security, product, analytics, and support teams. Privacy teams check notice, consent, minimization, and retention. Security and risk teams check scraping patterns, account abuse, API extraction, device clusters, false positives, and response policy. Product and support teams see where protection creates too much friction.
Make the loop measurable. Useful review signals include repeated requests per account, records returned per session, export volume, unusual filter walking, failed login or lookup patterns, new account clusters, challenge pass rate, support complaints, and confirmed false positives. Review those signals by surface, because a normal crawl pattern on public articles may be unacceptable on account recovery or coupon redemption.
The output should be a decision log, not just a dashboard. Keep the surface, owner, risk, chosen control, expected user impact, rollback condition, and next review date. This makes data harvesting prevention easier to maintain when teams change, products launch, or attackers adapt.
Conclusion
Data harvesting is useful when it is transparent, consent-based, and governed. It becomes a business risk when automated systems extract more than the site intended to expose, or when tracking and collection exceed what users reasonably expect.
In 2026, the practical response combines privacy governance, crawler policy, API controls, device and behavior signals, and risk-based verification. The goal is not to block every request. It is to keep legitimate access available while making repeated, abusive extraction harder to scale.
FAQ
1. What is an example of data harvesting?
A legitimate example is consent-based analytics collection for product improvement. A malicious example is a bot collecting prices, inventory, profile details, account metadata, or email addresses at scale.
2. Is data harvesting the same as web scraping?
No. Web scraping is one extraction method. Data harvesting is broader because it includes collection from many sources, dataset preparation, storage, and later use.
3. Can data harvesting be stopped completely?
No. Teams can reduce exposure and make abusive harvesting harder to scale with access control, rate limits, API quotas, crawler policy, device and behavior signals, monitoring, and risk-based verification.
4. Is robots.txt enough to stop harvesting?
No. Robots.txt helps communicate crawl preferences to cooperative crawlers, but it is not an access-control system. Sensitive data still needs server-side controls.



