# Agent Bot Defense: How Stealth Technology Changes Automation Risk
Agent bot defense now has to account for a different automation cost structure. Large language models and tool-calling protocols have made web automation less dependent on fixed scripts, bulk requests, and predictable DOM parsing. An agent bot can read page semantics, call browser or mobile tools, adjust the next action after feedback, and package proxy usage, CAPTCHA handling, and environment spoofing into a standardized toolchain.
For enterprise risk control, the decision surface becomes more complicated. Machine traffic is no longer one category. It includes attack-driven automation such as credential stuffing, bonus abuse, data theft, and inventory hoarding, but it also includes legitimate agents that help users compare prices, make purchases, plan trips, or update enterprise knowledge bases. Human traffic now carries different levels of trust as well. That mix forces enterprises to evaluate visitor identity, behavioral signals, task intent, and business impact together.
In the agent era, automation defense is no longer a simple question of whether something is a bot. The real question is whether a machine behavior has a trustworthy identity, reasonable intent, acceptable risk, and controllable impact. Agent bots and stealth technology are moving the attack-defense focus from static feature recognition toward multilayer trust evaluation. Enterprises need to see traffic identity, environment authenticity, interaction behavior, and business intent at the same time.
The discussion below tracks that shift from three angles:
- The bot evolution from scripts to AI crawlers and agent bots;
- The stealth stack now forming across browsers, protocols, devices, and toolchains;
- The defense model that connects identity recognition, environment judgment, behavior analysis, and business strategy.
Bot Evolution Toward the Agent Bot Era
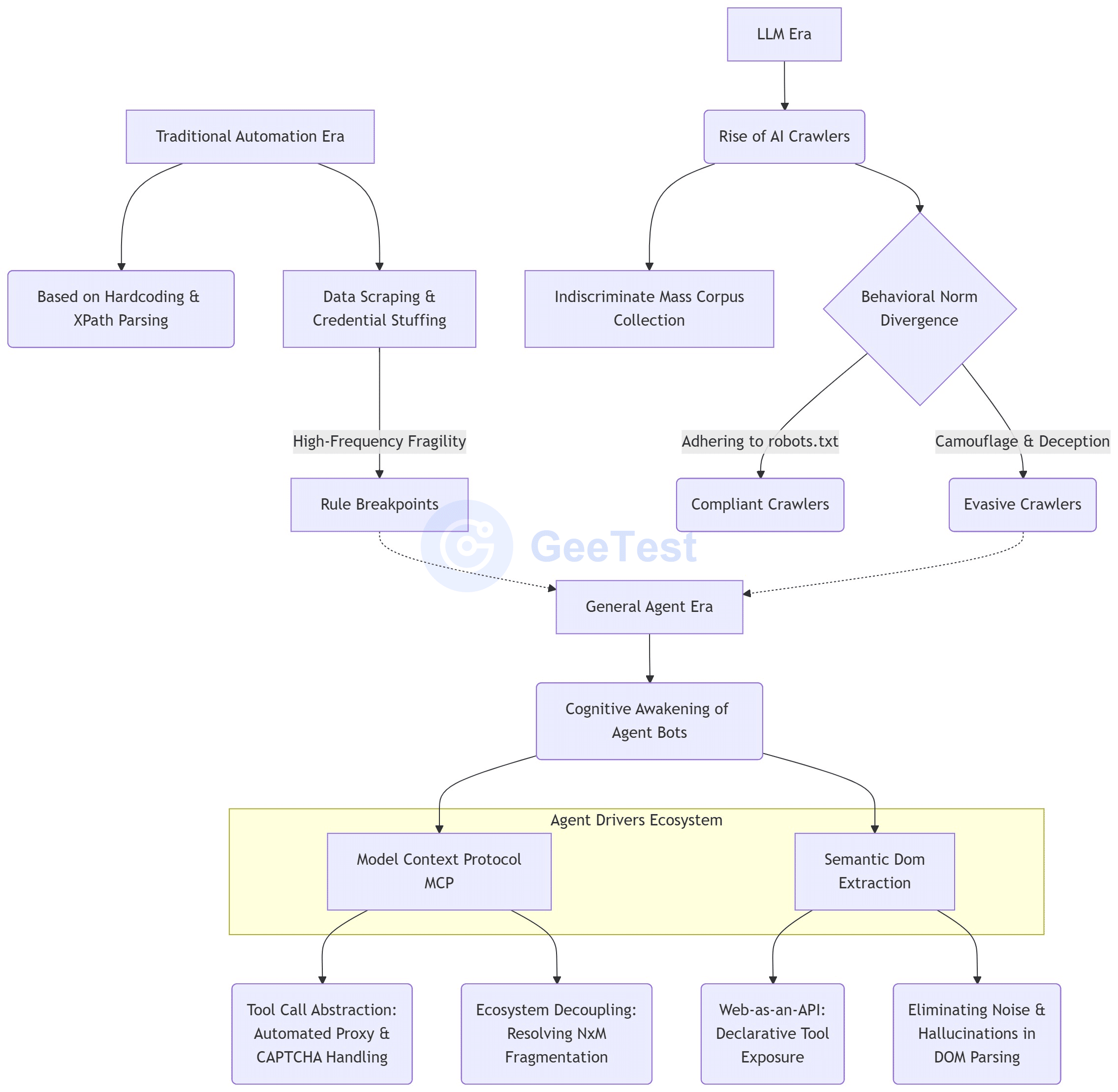
Internet automation keeps moving toward cheaper and more realistic business interaction. The agent bot is the latest expression of that shift.
The path is easier to read in three stages:
- Traditional bots based on fixed rules and state machines;
- AI crawlers built around large-model training data and real-time information collection;
- Agent bots with autonomous planning and tool-calling capabilities.
The difference between these stages is not only code architecture. It is a change in perception, decision-making, and execution. Traditional bots depend on paths written in advance by developers. AI crawlers expand the scope of content collection. Agent bots connect web pages, apps, APIs, proxies, CAPTCHA handling, and browser control into orchestrated task chains.
1. Traditional Bots: Script and Rule-Based Automation
Before large language models became widespread, internet automation was mainly dominated by traditional bots. The core logic of these programs was built on hard-coded execution scripts, preset state machines, and deterministic DOM parsing. For technical implementation, developers often used automation testing frameworks such as Selenium, Puppeteer, and Playwright to drive headless browsers. They also used cURL, Python Requests, or Go HTTP clients for protocol-level bulk requests.
Two economic use cases made traditional bots especially common. In large-scale data scraping, scripts used CSS selectors or XPath locators to walk through page nodes and pull out high-value data: ecommerce prices, flight schedules, financial quotes, job listings, and similar material. In credential stuffing and vulnerability scanning, attackers replayed leaked username-password pairs at speed, looking for accounts without MFA or with weak risk controls.
The tradeoff is rigidity. A traditional bot does not understand much context. Dynamic rendering, a frequently changing A/B test interface, or a small DOM adjustment can break the task chain. For defenders, that rigidity often leaves visible anomalies in request rate, navigation path, environment, and interaction.
2. AI Crawlers: Content Collection at Larger Scale
With generative AI, automated web interaction moved into a second stage: the AI crawler. Collection no longer stops at structured business data. It now reaches unstructured text, images, code, comments, knowledge bases, and document content, often for foundation model training, retrieval-augmented generation, vertical knowledge base updates, or real-time information supplementation.
Typical AI crawlers include OpenAI’s GPTBot, Meta’s Meta-ExternalAgent and FacebookExternalHit, and data collection programs deployed by companies such as Amazon and Google. On the surface, they look close to search engine crawlers. In practice, their collection purpose, frequency, content scope, and commercial impact can be more complicated.
In a more detailed classification system, machine access can be divided into AI Crawler, Search Engine Crawler, Page Preview, Monitoring Bot, Partner Integration, and malicious automation. The practical question is no longer only "is this visitor a machine?" It is whether the visitor declares its identity, follows robots.txt, controls crawl frequency, respects authorization boundaries, and avoids business or copyright risk.
AI crawlers have already split into different camps. Some transparently declare identity, follow site policies, and control frequency. Others disguise themselves as ordinary browser or mobile users, bypass site restrictions, and collect data that the site clearly does not want indexed or used for training. Anti-crawling and content-protection systems need to focus first on that second group.
3. Agent Bots: Intelligent Agents for Task Execution
The third threshold is task execution. Once models such as Claude, Codex, DeepSeek, Doubao, and Qwen gain internet access, browser control, file operation, and tool-calling capabilities, the workflow changes from "read this page" to "finish this task."
These agents quickly run into an infrastructure problem. Modern web pages are designed for human visual consumption. They contain cookie popups, side navigation, advertising scripts, dynamic components, and decorative DOM nodes. If raw HTML is fed directly into an LLM, context window space is wasted and the model is more likely to misread the page structure.
Tool-calling standards such as Model Context Protocol (MCP) are meant to reduce that friction between models and real web environments. MCP-style abstraction turns browser control, page extraction, proxy management, CAPTCHA handling, and data return into standard tools. The agent client expresses the task intent, while the backend toolchain handles headless browser launch, CDP communication, page-state reading, and action execution.
That packaging creates a new risk profile. Automation capabilities that once required skilled engineers are being turned into callable infrastructure for ordinary models. The barrier to automation falls, and attack scaling becomes faster.
4. Machine Traffic Classification in the Agent Era
When traffic ranges from crude scripts to advanced agents, enterprise defense teams first need a machine-traffic taxonomy. AI training crawlers, search engine crawlers, user-triggered AI assistants, messaging-app link previews, and malicious stealth bots should not share the same policy pool. A clearer taxonomy gives teams a way to identify, allow, limit, and audit machine access without treating every non-human visit as the same event.
A classification method better suited to the agent era starts with operating form, then evaluates business scenario:
- Bot operating form: whether the machine traffic runs autonomously in the background or is triggered by a real user’s behavior.
- Bot business scenario: whether the traffic serves search, AI training, security scanning, monitoring, link preview, RSS fetching, social media management, or an internal/customized call that cannot be easily categorized.
- Governance strategy: the same type of machine access does not always need to be blocked, but it must be identifiable, rate-limitable, auditable, and moved into a stronger verification chain when it reaches high-value business actions.

In modern machine classification, "machine access" becomes an operational label system rather than a single defensive bucket.
| Operating Form | Business Scenario | Behavior / Typical Logic | Example Programs |
|---|---|---|---|
| BOT | AI_CRAWLER | Crawls full-site data at large scale in the background to build AI training datasets. | GPTBot, CCBot |
| AI_SEARCH | Periodically or in real time fetches data to update the knowledge base of AI search engines. | PerplexityBot, OAI-SearchBot | |
| SEARCH_ENGINE_CRAWLER | Continuously crawls webpages to build and refresh search engine indexes. | Googlebot, bingbot | |
| SEARCH_ENGINE_OPTIMIZATION | Commercial crawlers traverse site networks and analyze backlinks, keywords, and rankings. | AhrefsBot, SemrushBot | |
| ARCHIVER | Automatically records and permanently preserves the current state of webpages as historical snapshots. | archive.org_bot | |
| SECURITY | Scans sites for known vulnerabilities, exposed ports, or malicious-code indicators. | Nmap, CensysInspect | |
| MONITORING_AND_ANALYTICS | Simulates scheduled visits to check whether a site is available and whether loading performance is normal. | Pingdom, Datadog Agent | |
| AGGREGATOR | Regularly fetches specified sites, such as news or ecommerce pages, and aggregates information for display. | NewsNow, price-comparison crawlers | |
| ADVERTISING_AND_MARKETING | Automatically extracts page context to match advertising inventory or marketing software. | AdsBot-Google | |
| ACADEMIC_RESEARCH | Runs large-scale crawling for research institutions, such as web topology research. | University research crawlers | |
| ACCESSIBILITY | Automatically traverses website pages to check whether accessibility declarations are missing. | Accessibility scan tools | |
| AGENT | AI_ASSISTANT | A real user enters a URL in an AI chat interface and triggers AI access to the page. | ChatGPT-User |
| PAGE_PREVIEW | A user sends a link in messaging software and instantly triggers a generated preview card. | Slackbot, Twitterbot | |
| FEED_FETCHER | A user actively refreshes or fetches RSS subscription sources through a client. | AppleCoreMedia(Podcast) | |
| SOCIAL_MEDIA_MARKETING | A user schedules publication or manages post content through a third-party tool. | Bufferbot, Hootsuite | |
| Hybrid form | OTHER | The visitor has a valid identity, but its behavior is too complex to fit a single category. | Internal microservice calls, custom scripts |
In the agent era, enterprises need a governance model that supports identification, allowlisting, rate limiting, verification, downranking, and blocking at the same time. A single bot rule can no longer handle all non-human traffic.
Stealth and Counter-Detection Are Moving Down the Stack
As defenders tighten their detection network, attackers and compliant automation toolchains keep evolving too. Automation programs have moved from rough WebDriver wrappers to customized low-level communication that can even abandon the Chrome process relationship. The escalation has a consistent direction: adversarial technology keeps moving deeper into the stack.
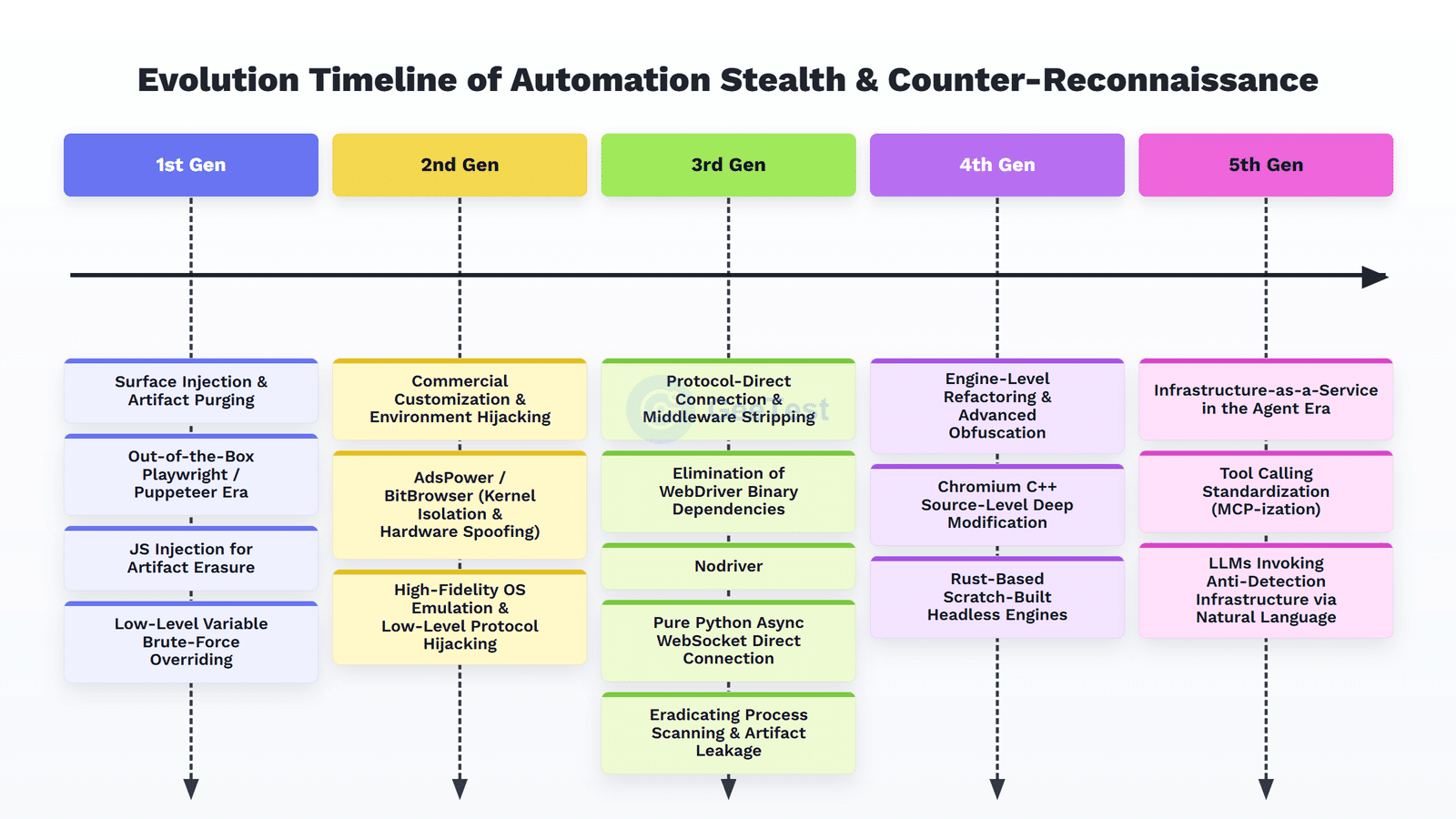
1. Native Framework Exposure and Surface JavaScript Injection
Early headless browser environments used unmodified native Playwright or Puppeteer, which are exposed in front of modern risk-control systems. They set navigator.webdriver to true by default and lack the rendering parameters of real graphics hardware.
To hide these features, the community evolved surface-level JavaScript injection methods. In Node.js, a typical example is puppeteer-extra-plugin-stealth. In Python, an early example is undetected-chromedriver. These tools intercept page loading events and inject JavaScript to overwrite the navigator object or obfuscate fingerprints. undetected-chromedriver also uses binary patches to modify feature variable names in the ChromeDriver executable, bypassing some detection logic based on fixed strings and process features.
However, surface injection is fragile. JavaScript hooks can fail in nested iframes, fast page jumps, sandbox isolation, or early script execution timing. When that happens, automation features leak.
2. Commercial Anti-Fingerprint Browsers and Environment Hijacking
When open-source patches proved insufficient against complex device-fingerprint probes, gray-market operators and advanced automation tools turned to commercial fingerprint browsers such as AdsPower and BitBrowser. These products modify the browser kernel layer, provide highly isolated browser environments, and spoof dozens of hardware-related parameters such as Canvas, WebGL, fonts, audio, and WebRTC.
This commercial packaging integrates proxies, fingerprints, accounts, cookies, environment isolation, and batch task management into an operational platform. For attackers, it lowers the barrier to scaling. For defenders, it makes a single browser fingerprint or single IP reputation signal less reliable.
3. From WebDriver-CDP to Nodriver-CDP
For a long time, middleware running in a WebDriver-CDP hybrid mode has been a major detection target for risk-control systems. Process scanning, polluted launch parameters, exposed debugging ports, and driver binary features are all detection points. To cut the link with WebDriver, a new generation of tools began moving toward lower-level protocol control.
This created a technical jump from indirect control to direct native Chrome-CDP control. One representative framework, currently popular in the Python community, is Nodriver.
Built by the core developer behind undetected-chromedriver, Nodriver removes the dependency on the ChromeDriver binary. Its core logic is that the Nodriver-CDP mode starts the system’s native Chrome process with parameters closer to those of an ordinary user, then uses asynchronous Python code to establish a direct WebSocket connection to the Chrome DevTools Protocol.
This weakens three traditional features: ChromeDriver process traces, abnormal launch parameters, and WebDriver variable pollution. It does not make automation impossible to identify, but it forces defenders to move from "identifying an automation framework" to "evaluating the consistency of the session, transport, environment, and behavior."
4. Engine-Level Rebuilds: Chromium Modification and Rust Lightweight Engines
When risk-control engines begin using timing analysis, hardware features, and rendering differences for detection, stealth technology continues to move lower.
One type of heavily modified browser tool goes deep into Chromium’s C++ source code. It patches and recompiles the rendering engine, device enumeration, fingerprint exposure points, and network stack. Because the spoofing is completed at the binary and engine level, traditional JavaScript hook detection becomes difficult.
Another route is lightweight engine reconstruction. Traditional Headless Chrome is complete but resource-intensive. Some tools begin using Rust, V8, HTML5 parsers, or custom rendering pipelines to build lighter headless execution environments, while handling anti-tracking, Navigator rewriting, TLS fingerprints, and network features inside the engine. These tools may not fully reproduce a real browser, but they are enough to challenge detection that relies on Chrome-specific implementation differences.
5. Stealth Packaging in the Agent Era
In the AI agent era, an LLM does not need to understand complex Python Nodriver scripts or browser-fingerprint details. The latest adversarial evolution is to standardize anti-detection capabilities as API toolsets that models can call. In other words, these capabilities become MCP-like infrastructure.
At this stage, real-environment hijacking tactics will upgrade further. Some advanced frameworks run the target app directly on real Android devices, deeply virtualized Android/iOS environments, or mobile hosted environments. They combine port forwarding, debugging channels, and system-level automation interfaces for continuous control. Compared with parameter simulation in desktop headless browsers, these schemes can provide higher consistency and realism.
For example, the approach mentioned in the previous article at https://mp.weixin.qq.com/s/wx_88wuutJI2S0QsTTEFNg belongs to this line of thinking.
These schemes use real physical devices or high-fidelity environments as their base, which can improve the credibility of system fingerprints. But they also create new detection opportunities: real devices, accounts, networks, behaviors, and business paths must remain consistent over time. Once they operate at scale, they can expose abnormal resource reuse, behavior templates, task rhythm, and target selection.
Defense Architecture for the Agent Bot Era
As stealth technology sinks into browser kernels, network protocol stacks, and mobile runtime environments, defenders can no longer rely only on application-layer DOM parsing, JavaScript environment probes, or a single User-Agent rule. Anti-automation in the agent era must upgrade from "identifying a tool" to "verifying whether the whole session is trustworthy."
Transport-layer fingerprinting, endpoint environment awareness, behavioral biometrics, and business risk orchestration correspond to protocol-layer recognition, device-fingerprint environment recognition, behavioral verification, and risk decisioning. GeeTest’s anti-automation, human-bot verification, device risk identification, behavioral verification, and decision engine capabilities form this type of risk-control decision chain. They can serve as verification and judgment capabilities at critical business nodes, helping enterprises evaluate environment trust, behavior trust, and intent trust.
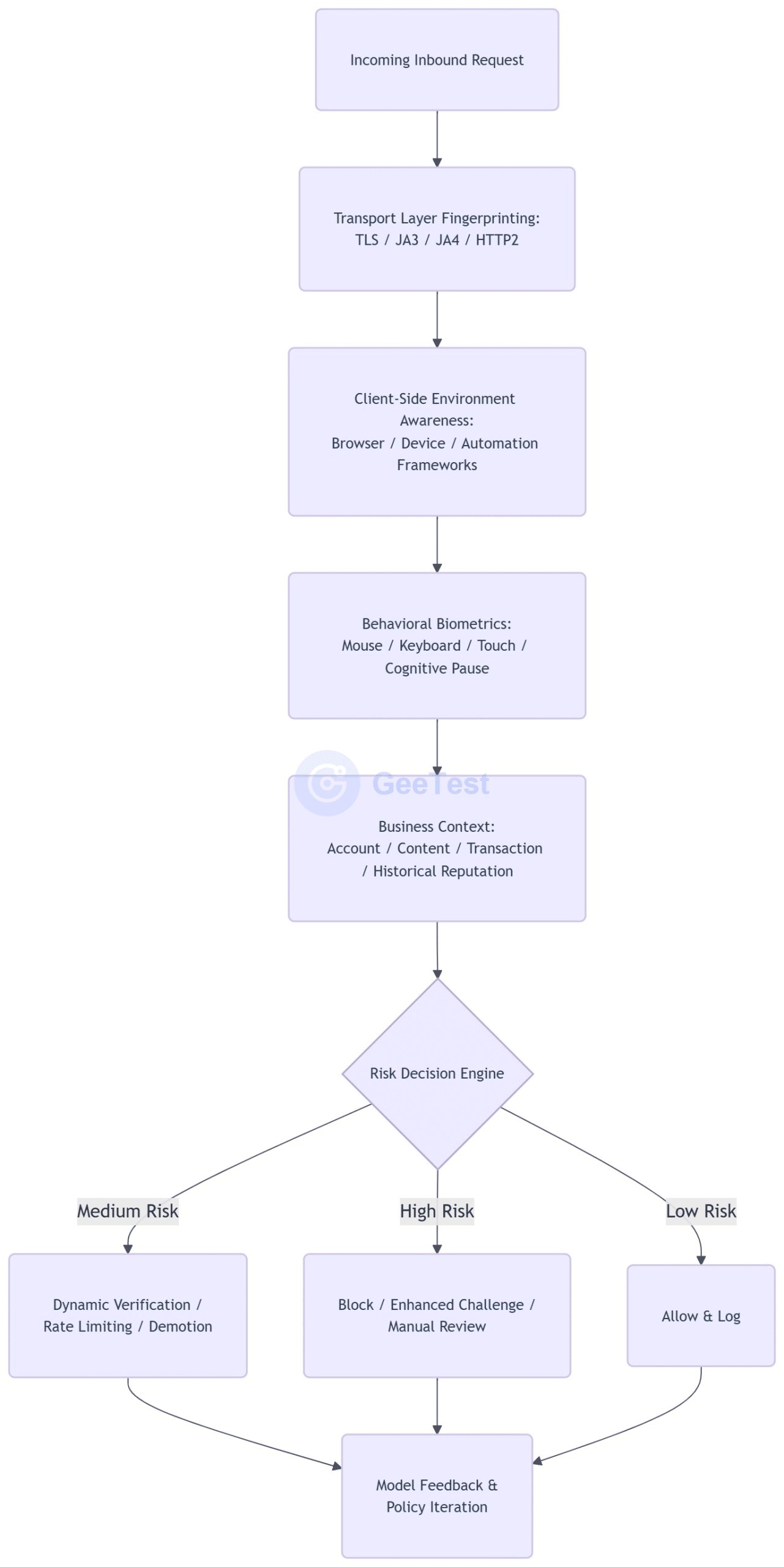
1. From JA3 to JA4 TLS Fingerprinting
In the modern internet, almost all important communication is wrapped in TLS/SSL encryption. Encryption protects content, but it cannot hide the structural features of communication behavior itself. In the earliest phase of TLS connection establishment, when the client sends a ClientHello handshake packet, the client declares in plaintext the low-level encryption library it supports, such as BoringSSL used by Chrome, NSS used by Firefox, or OpenSSL commonly used by Python scripts. Because different software stacks implement these details differently, risk-control systems can extract the low-level parameters exposed before the encrypted tunnel is established and generate a unique fingerprint. This allows them to separate Python crawler scripts or C2-controlled malware trying to disguise themselves as ordinary browsers without decrypting any payload.
For the past several years, a widely adopted baseline technology has been the JA3 fingerprint, invented by the Salesforce team. The core logic of JA3 is to extract five key fields from the ClientHello message: TLS version, supported cipher suite list, supported extensions, elliptic curve parameters, and elliptic curve point formats. The algorithm strictly concatenates the decimal codes of these fields in sending order into a long string, then calculates its MD5 hash to produce a fixed 32-character fingerprint identifier. Its logic can be simplified as:
JA3 = MD5(TLSVersion, Ciphers, Extensions, EllipticCurves, EllipticCurvePointFormats)
As adversarial pressure increased, JA3 exposed serious architectural weaknesses. To address this shortcoming, the FoxIO team, founded by an original co-inventor of JA3, introduced the JA4 fingerprint standard. The shift can be read as an architectural move from quick client-type separation toward a more readable signal layer that is better suited to randomized browsers, proxy chains, and complex client-source environments.
Table 3: Core architectural evolution of transport-layer network fingerprint tracking technology, JA3 vs. JA4.
| Comparison Dimension | JA3 | JA4 |
|---|---|---|
| Core input | TLS ClientHello version, cipher suites, extensions, elliptic curves, and elliptic curve point formats. | Enhanced fields on top of TLS fingerprinting, improving standardization and cross-protocol readability. |
| Advantage | Simple to implement and useful for quickly distinguishing abnormal clients, scanners, and non-browser clients. | Better suited to modern browser randomization, proxy chains, and complex client-source environments. |
| Limitation | Sensitive to field ordering and vulnerable to randomization or camouflage. | Needs to be combined with HTTP, device, behavior, and business signals. |
| Best use | Rapidly identify clearly abnormal scripts, scanners, and non-browser clients. | Serve as one layer in a multi-signal risk-scoring system, not a standalone verdict. |
Transport-layer fingerprinting provides a first layer of risk signals before content is decrypted. Against advanced agent bots, however, the table also shows why TLS fingerprints cannot carry the final decision by themselves. A more effective method is to merge JA3/JA4, IP reputation, proxy features, device fingerprints, and behavioral trajectories into the same risk-scoring system.
2. Behavioral Biometrics Against CDP Interaction Spoofing
From WebDriver to Nodriver, automation tools increasingly communicate with browsers through CDP, or Chrome DevTools Protocol. Many attackers mistakenly believe that avoiding the WebDriver identifier is enough to bypass major detection. In reality, as long as the task target needs real UI interaction with a web page, such as clicking buttons, filling forms, dragging sliders, or completing verification, the behavior layer still exposes many risk signals.
In earlier front-end attack and defense, ordinary automation scripts often used JavaScript’s element.click to trigger clicks. The isTrusted property of this event object is marked by the browser as false by default, so simple risk-control scripts can intercept it immediately. To break through this limitation, advanced bots use low-level CDP commands such as Input.dispatchMouseEvent or Input.dispatchKeyEvent. From the browser kernel’s point of view, clicks and key presses forged by these commands are equivalent to real physical hardware input and can generate flawless events with isTrusted = true.
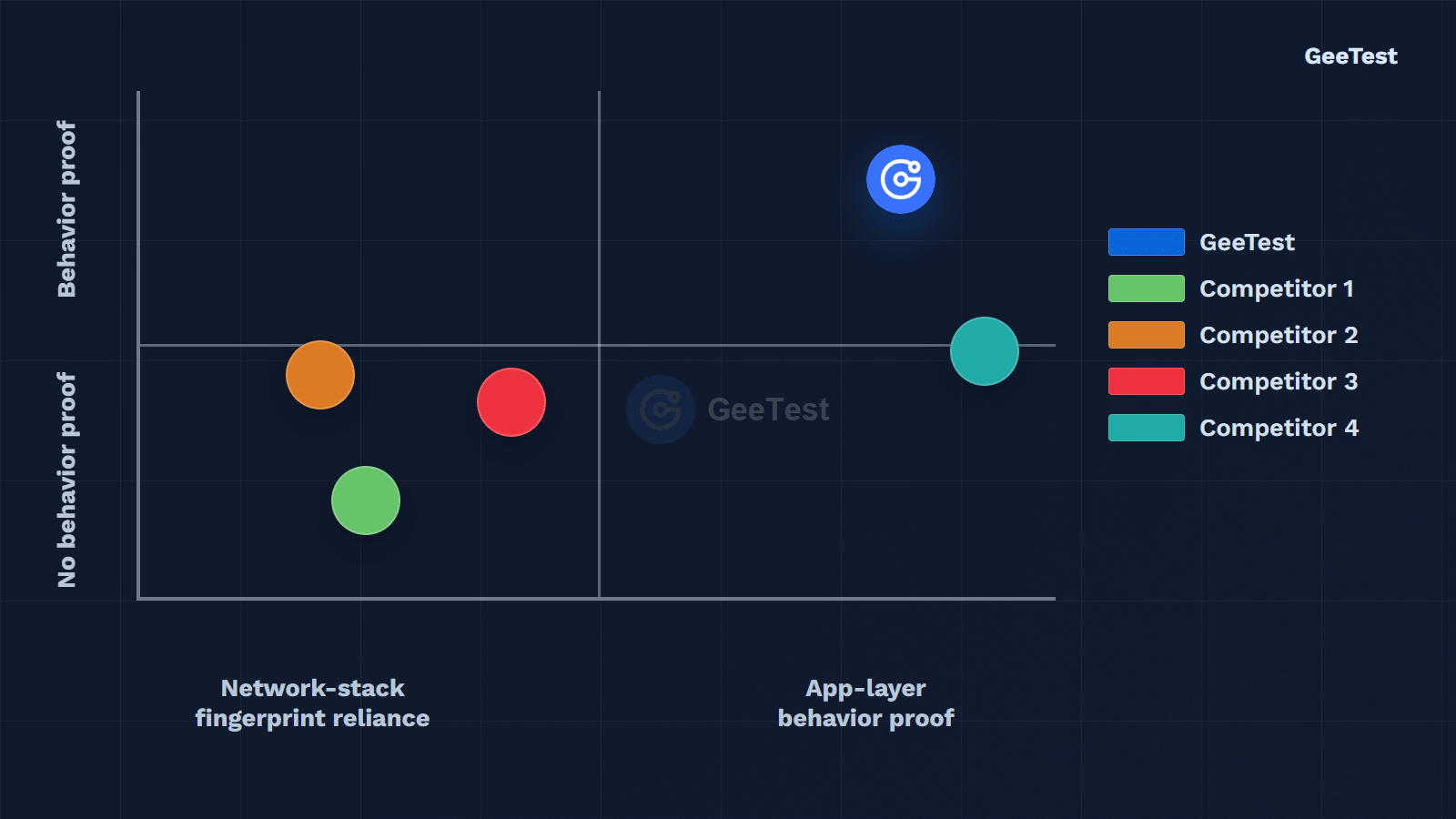
Figure: Behavioral challenge strength versus network-stack dependence in agent bot defense.
Behavioral biometrics becomes important at this point. In this positioning view, the stronger quadrant is not defined by a single browser or network fingerprint. It is defined by whether the defense can verify behavior at the application layer while still considering network and environment signals. Modern risk-control engines represented by GeeTest do not stop at static attributes. They continuously monitor the micro-dynamic patterns of interaction behavior.
Three traces are especially useful here. The first is mouse trajectory. Real movement rarely travels as a perfect straight line between two points. It has speed changes, initial acceleration, a slowdown near the target, and small curve deviations. Mechanically triggered CDP coordinate commands often miss those details.
Typing adds another layer. "Flight time" and "dwell time" expose biometric signals that become difficult to imitate when a bot injects text at a constant speed or uses random intervals that do not resemble a real typing rhythm.
Cognitive pauses matter as well. A real user often stops to read, locate an element, or think through a form or verification task. Automation scripts tend to chase efficiency, so they often launch continuous high-speed interactions as soon as the page finishes rendering.
Even if advanced agents or AI crawlers hide environment features through low-level modifications and generate isTrusted = true click events through CDP, behavioral recognition engines can still classify them as high risk when mouse, keyboard, touch, and cognitive rhythm lack the natural variation of human interaction. The system can then trigger dynamic verification, rate limiting, business downranking, or blocking.
3. From Detection Signals to Business Strategy
The difficulty of defending against agent bots is not only recognition. The harder operational question is what to do after recognition. Enterprises need to connect transport-layer, environment-layer, behavior-layer, and business-layer signals into a unified decision engine, then choose actions according to business value and risk intensity.
For high-value nodes such as login, registration, coupon claiming, payment, withdrawal, bulk content access, search result scraping, and inventory queries, a layered response strategy is recommended:
- Low-risk sessions: allow and continue sampling to avoid excessive disruption to real users.
- Medium-risk sessions: trigger GeeTest real-time behavioral verification, dynamic challenges, rate limiting, or key data downranking.
- High-risk sessions: block core actions, require stronger device proof, or move the session to manual review.
- Coordinated-risk sessions: correlate accounts, devices, IPs, proxies, target content, and operation paths for batch handling.
This is also the biggest difference between modern anti-automation capability and traditional CAPTCHA. CAPTCHA should not be an isolated popup. It should become a dynamic action inside the risk decision chain. Only when challenge results, behavioral trajectories, device trust, and business context enter the same risk-control loop can enterprises balance allowing legitimate agents, limiting gray automation, and blocking malicious bots.
Conclusion: Risk Control for the Agent Economy
From hard-coded scripts and XPath parsing to AI crawler content collection, and then to agent bots with tool calling and dynamic planning, internet automation is moving from "request automation" to "task automation." This means defense methods that rely on static features, fixed rules, and single-point CAPTCHA will find it increasingly difficult to cover real risk.
The operating reality is changing: future visitors will include humans, legitimate agents, gray automation, and malicious bots at the same time. Risk-control systems need an explainable, layered trust-evaluation mechanism for machine traffic that can connect with business actions and support more refined identification, decision-making, and governance.
For security, risk-control, anti-crawling, and growth teams, the next build phase can be reduced to four priorities:
- Build machine traffic taxonomy to distinguish legitimate automation, gray automation, and malicious automation.
- Unify TLS/HTTP fingerprints, device fingerprints, behavioral biometrics, and business context into risk scoring.
- Deploy dynamic verification, rate limiting, downranking, stronger checks, and blocking strategies at key business nodes.
- Continuously evaluate false positive rate, bypass rate, verification pass rate, business loss, and changes in attack cost.
Within this system, GeeTest’s anti-automation human-bot verification, device risk identification, behavioral verification, and decision engine capabilities fit the roles of "dynamic decision action" and "behavior trust judgment." They help enterprises judge each visit in the agent era with more detail: whether access is trustworthy, whether it should be allowed, whether verification should be triggered, and whether blocking is required.
Agent bots and stealth technology will continue to evolve. Defenders need trust infrastructure that keeps learning, adds layers over time, and steadily raises the cost of attack, while still supporting long-term governance, dynamic recognition, and strategy orchestration.