The mobile proxy problem usually shows up as a contradiction in the logs. The IP belongs to a mobile carrier, often on 4G, 5G, LTE, or a similar cellular network. The session, though, may behave like scripted traffic. To the app, it can look like one more phone on a mobile network, not a cloud host or obvious automation box.
That split is why mobile proxies are hard to handle. The carrier signal can be real, while the user journey behind it is not. A better review question is: would a real mobile user have left this full trail, not just this one IP?
Why do carrier IPs look trustworthy?
- The IP range can belong to a real mobile carrier.
- Shared addressing and CGNAT make one IP represent many users.
- Geography and ASN signals may look normal even when the session behavior is not.
- IP reputation should support the case, not decide it alone.
Mobile proxies work as cover because the carrier part of the record is not fake. Mobile networks use shared addressing, dynamic assignment, and carrier-grade network address translation. RFC 6598 defines shared address space used in carrier-grade NAT contexts. It is not a mobile-proxy document, but it is a useful reminder that shared-address environments make IP-only decisions fragile.
1. What makes a mobile proxy different
A datacenter proxy often leaves a hosting trail. A mobile proxy borrows the carrier edge. The request may bring a mobile ASN, a plausible geography pattern, and an IP range where normal consumer traffic also lives.
Mobile teams may use that setup for QA, localization checks, or ad verification. Abuse teams like the same property for a different reason. Signup attempts, credential attacks, scraping requests, coupon abuse, and social account activity can arrive from exits that do not immediately announce themselves as automation.
2. Why carrier IPs complicate simple blocking
The risky shortcut is to treat a suspicious carrier IP as if it belonged to one bad actor. It may not. Real users move between cells, reconnect, share public IPs, and appear from infrastructure that changes underneath them. Cloudflare has written about the collateral effects of treating shared IP addresses too aggressively in CGNAT environments: one IP may represent many users.
Keep IP reputation in the case file. Do not let it become the whole case.
How does abuse traffic hide behind carrier exits?
- Automation tooling initiates the request.
- A proxy pool rotates the session through carrier-facing exits.
- The target app sees a mobile network context.
- Risk evidence appears later in timing, accounts, devices, retries, and outcomes.
In a mobile-proxy abuse workflow, the operator wants the app to see the carrier exit, not the automation environment behind it. Traffic moves from tooling, through a proxy pool, out through carrier exits, and into the target app. The app receives a carrier-facing request. The campaign leaves its harder-to-hide marks elsewhere: timing, accounts, devices, target objects, retries, and outcomes.
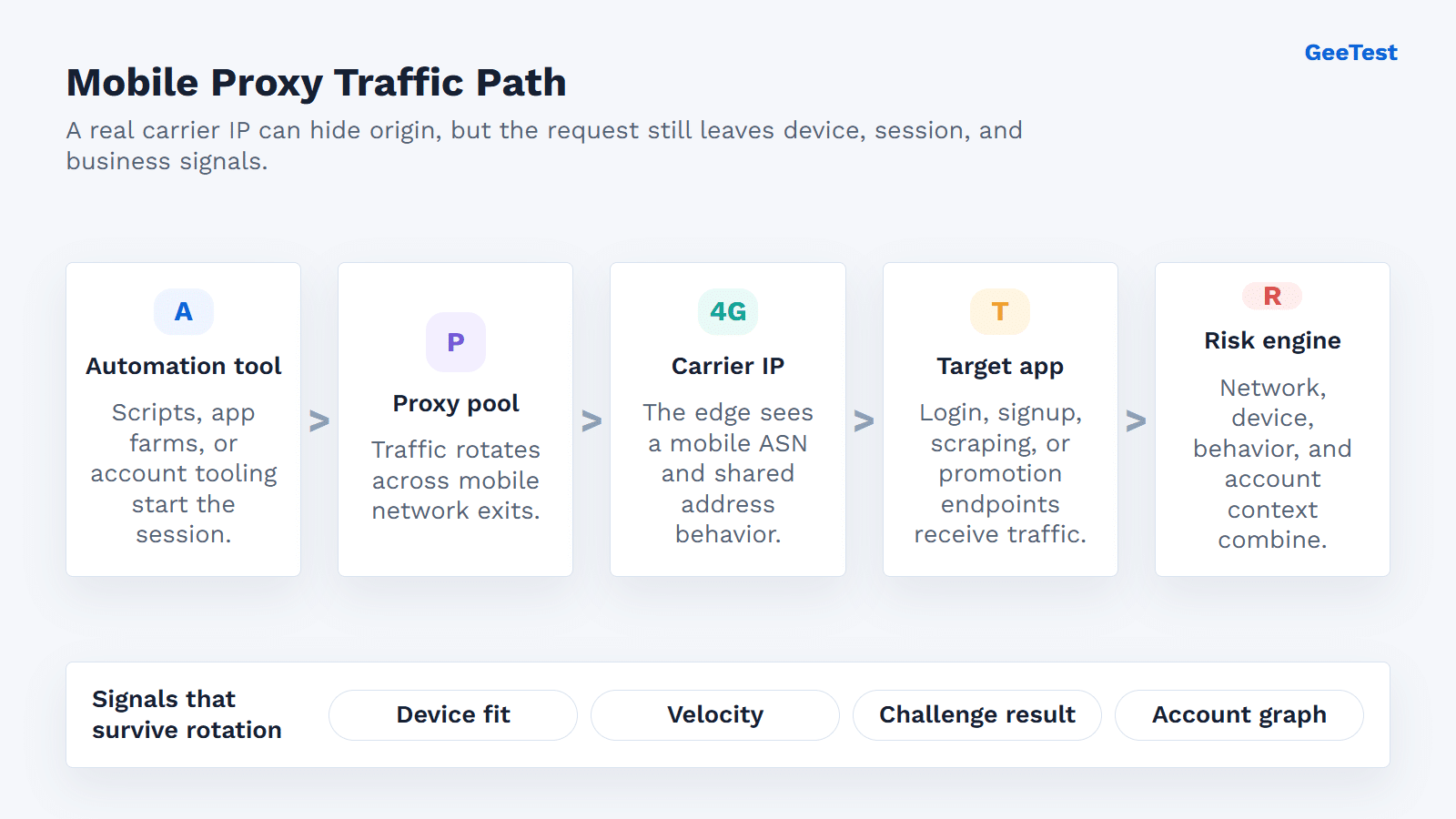
1. The target sees a mobile network, not the operator
At the edge, the application may record carrier geography, mobile ASN, request headers, device signals, and session behavior. It usually cannot see the workstation, script, or service controlling the traffic. One request may be boring. Twenty related requests may not be.
2. Rotation changes the evidence, not the intent
Rotation changes one column in the log. It does not erase intent. The same campaign may reuse account attributes, device patterns, timing windows, payment instruments, coupon codes, SKUs, login targets, or challenge behavior. Treat rotation as context in a broader case file, not as a verdict.
How do carrier, residential, VPN, and datacenter routes differ?
- Carrier exits can share infrastructure with ordinary mobile users.
- Residential routes may resemble consumer ISP traffic, but supply quality varies.
- VPNs can signal privacy, travel, or policy choice rather than abuse.
- Datacenter routes are easier to label, but hosting alone is not a verdict.
- Confirmed botnets or compromised hosts usually require faster escalation.
Proxy labels are useful for describing infrastructure. They are weak as final enforcement rules. A mobile proxy may exit from a real carrier IP, so the first response should be corroboration, not automatic blocking. A residential proxy may look like consumer ISP traffic, but consent and supply-chain quality vary. A VPN can be a privacy or travel choice for legitimate users. A datacenter proxy is often easier to label, but a hosted request is not always malicious. Botnets and compromised hosts sit in a different risk category; once confirmed, they usually deserve faster escalation because the legal and security risk is higher.
The distinction matters because a mobile proxy does not make an attacker invisible. It changes which evidence is likely to be useful.
Where do proxy-driven attacks create pressure?
- Account creation, credential stuffing, and repeated login attempts.
- Scraping, inventory monitoring, scalping, and promotion abuse.
- Support volume, checkout friction, distorted demand, and policy-tuning workload.
Search results around this topic often tilt toward provider pages and operator talk: automation, scraping, social account scaling, mobile app access, and location-sensitive workflows. A fraud team should read that material sideways. It is not a procurement guide. It hints at the places where abuse pressure may surface.
1. Account abuse and credential attacks
Credential stuffing, fake account creation, and repeated login attempts all become harder to tune when the source appears distributed. A small set of obvious IPs is easier to rate-limit. A rotating mobile exit pool pushes the review toward account graphs, device continuity, password-attempt rhythm, and challenge outcomes.
For broader automation-abuse taxonomy, the OWASP Automated Threats to Web Applications project is a useful non-provider reference point.
2. Scraping, scalping, and promotion abuse
Scraping, inventory monitoring, promotion abuse, and high-value event activity can also attract mobile-proxy traffic. The damage is often operational before it is technical: distorted inventory signals, leaked coupons, fake demand, checkout friction, more support volume, and worse treatment of legitimate customers.
GeeTest has a related public case article on fighting scraping and credential stuffing. Treat it as related context for bot and account-abuse pressure, not as proof that every mobile-proxy incident follows that pattern.
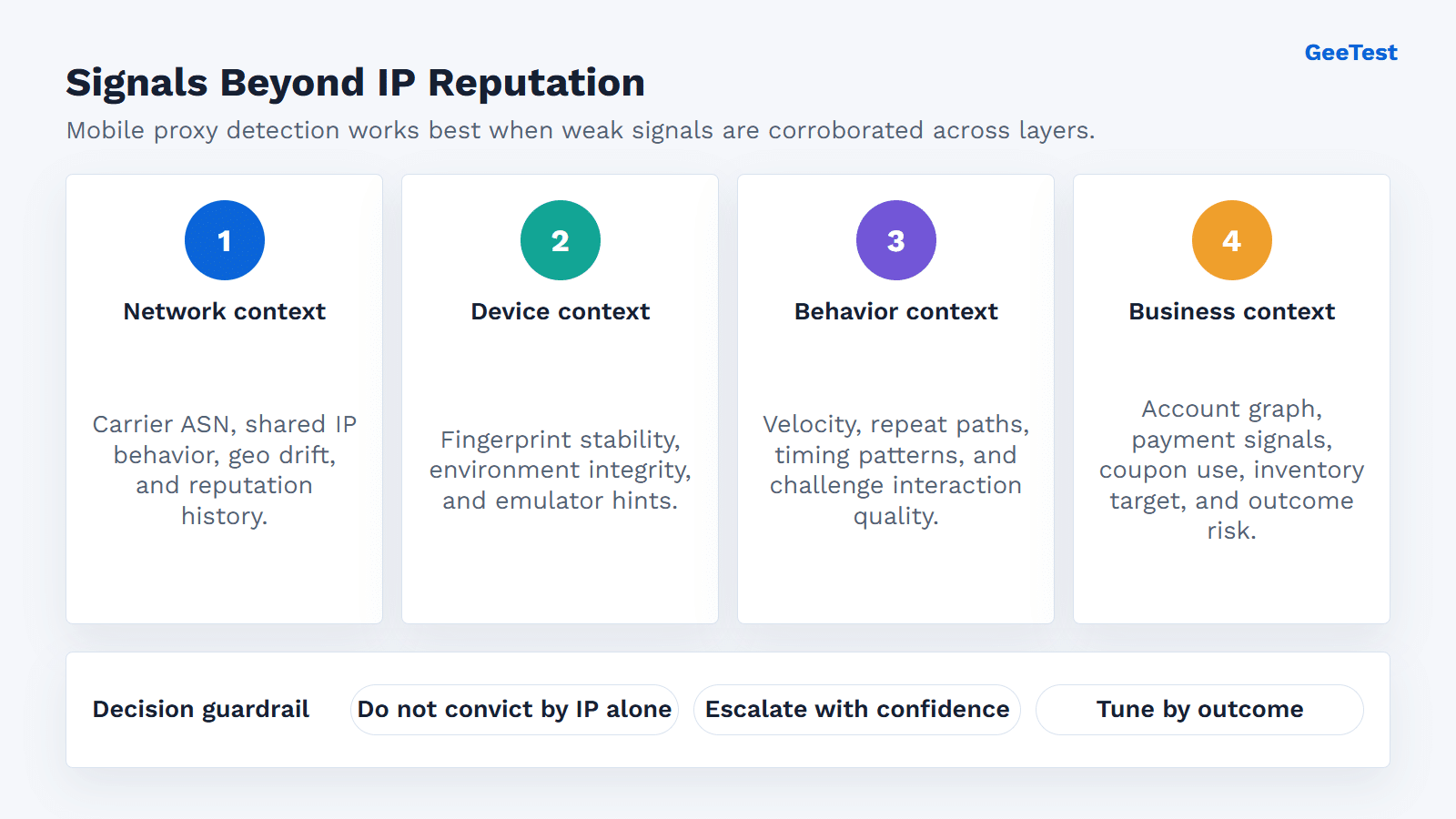
Which signals work beyond IP reputation?
- Device and browser consistency.
- Session velocity and behavior quality.
- Challenge outcomes and retry rhythm.
- Account graph patterns.
- The business object under attack.
By the time a mobile-proxy campaign reaches a risk queue, the IP may be the least interesting line in the record. A carrier address can be normal. A strange browser signal can be noise. A failed challenge can happen to a real user. The case gets stronger when small signals start agreeing: unstable device identity, odd timing, repeated target objects, poor interaction quality, and suspicious account relationships.
1. Device and browser consistency
Device intelligence gives the risk team another angle when the network layer is ambiguous. Look for device identifiers, browser environment, emulator hints, fingerprint stability, and whether the journey keeps a believable continuity from page to page. GeeTest Device Fingerprinting can be used as one device identity layer in the risk stack. It should support the decision, not replace the rest of the investigation.
2. Session velocity, behavior, and challenge outcomes
Behavior is where many neat proxy stories start to fray. Do not stop at requests per minute. Review page order, repeated form motions, navigation depth, retries, idle time, and what happens after verification. Challenge data is most useful when it stays attached to the session: pass rate, solve quality, retry rhythm, and sudden volume shifts may contradict the tidy story told by the IP address.
3. Account graph and business-risk context
Business context often does the work that network labels cannot. A campaign may rotate exits while chasing the same promotion, SKU, booking slot, payment instrument, referral code, or login target. Low-reputation accounts may repeat the same path across different IPs. Retries may pile up around one endpoint. At that point, proxy rotation loses much of its cover.
A typical review path starts with the object under pressure, not the proxy label. If new accounts keep touching the same coupon, login target, or high-value item, the team can compare account age, device continuity, verification behavior, and post-verification outcomes before making an enforcement decision. That sequence keeps the investigation close to business impact and helps avoid punishing ordinary mobile users who only share a noisy carrier route.
How can teams reduce false positives?
- Treat shared carrier IPs as caution signals, not automatic verdicts.
- Corroborate with device, behavior, challenge, account, and business-risk evidence.
- Use step-up verification for uncertain sessions.
- Limit or block only high-confidence abuse.
- Review outcomes after enforcement and retune thresholds.
Mobile proxy defense can fail by being too confident. A strict carrier-IP block may catch some abuse and still be the wrong move if it sweeps in real users who share infrastructure, move between cells, or reconnect from a noisy mobile network.
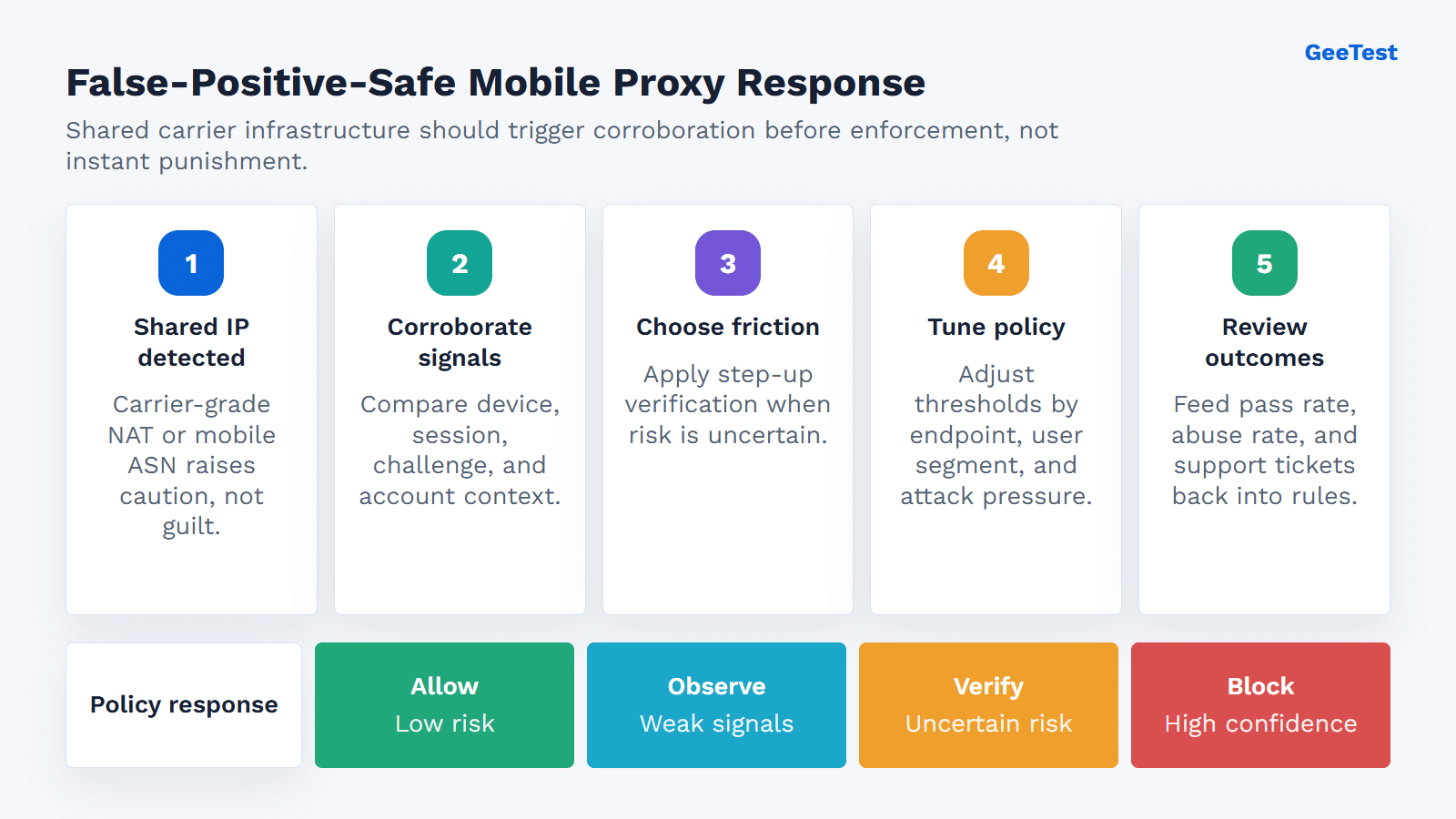
1. Treat shared mobile infrastructure as a caution signal
A shared carrier IP should raise caution, not trigger an automatic ban. Before enforcement, ask what else supports the case: device consistency, account age, behavior, challenge results, transaction value, endpoint sensitivity, and recent attack pressure.
2. Use risk-based verification before hard blocking
When confidence is mixed, step-up verification is usually safer than immediate blocking. GeeTest Adaptive CAPTCHA can add risk-adaptive verification at sensitive touchpoints, while the Business Rules Engine can support policy outcomes such as allow, observe, verify, limit, or block.
The operating model is proportional response. Low-risk mobile sessions pass with little friction. Uncertain sessions receive verification. High-confidence abuse gets limited or blocked.
What should fraud teams check first?
- Map the attacked object: account, promotion, SKU, booking slot, referral code, or login target.
- Compare device continuity, velocity, and interaction quality.
- Review challenge outcomes and post-verification behavior.
- Choose observe, verify, limit, or block based on confidence.
- Measure abuse rate, pass rate, support impact, and attack pressure after enforcement.
Mobile proxies force detection away from IP-only rules and toward behavior, device integrity, and business-context correlation. Keep IP reputation as evidence, not a final sentence, because mobile IPs are shared and dynamic. Then compare device continuity, velocity, and interaction quality before treating rotation as intent.
A workable triage sequence is usually narrow at the start. First, map the activity to the business object being attacked: account, promotion, SKU, booking slot, referral code, or login target. Next, decide whether the evidence supports observation, step-up verification, rate limiting, or blocking. After enforcement, review pass rate, abuse rate, support complaints, and attack pressure. Those outcomes tell the team whether the rule is too loose, too harsh, or aimed at the wrong object.
The goal is not perfect proxy labeling. The practical goal is to make abuse expensive while keeping real mobile users out of unnecessary friction.
FAQ
These answers are written for risk teams that need a quick policy check before tuning mobile-network rules.
1. Are mobile proxies always malicious?
No. They can support mobile QA, localization checks, and ad verification. The risk is dual use: the same carrier-facing infrastructure can also hide account abuse, scraping, credential attacks, or promotion abuse.
2. Why not block mobile carrier IPs directly?
Because a carrier IP may represent many real users and may change often. A hard block can create false positives, so the decision needs support from device, behavior, session, and business-context signals.
3. What should fraud teams look at first?
Start with IP reputation and carrier context, then ask whether independent evidence agrees: device fingerprinting, session velocity, browser or app environment, challenge outcomes, account graph, and the business object under attack.